


Поиск белков в ДНК человека
Материал излагается в доступной для не профессионалов форме, поэтому не стоит ждать сложных математических выкладок и эталонных результатов. Для получения первоначальных сведений о ДНК рекомендуется ознакомится с первой частью исследования или с полноценными трудами по генетике.
Одной из важнейших научных задач является создание карты ДНК человека, которой можно будет пользоваться как справочником. Прообразом такой карты сегодня служит карта хромосом. Хромосомы это куски ДНК, на которое ДНК разбивается на время создания своей копии. После деления из хромосом опять получается цельное ДНК.
Если считать что ДНК состоит из слов, таким словом является кодон. Кодон, в свою очередь, это три последовательно расположенных азотистых основания (нуклеотида). При первом знакомстве c кодонами становится известно, существуют старт и стоп кодоны, которые начинают и заканчивают кодирование белков в ДНК и РНК. На первый взгляд построение карты ДНК является простой задачей. Сложность одна, старт кодон это одна последовательность, а стоп кодов три последовательности. Существует один кодон безусловно останавливающий кодирование и две условных, которые могут останавливать или не останавливать кодирование.
При написании старт и стоп кодонов используется буква U (урацил), которая используется в РНК, а не ДНК, значит в РНК с аденином соединяется урацил (U), а не тимин (T).
Получается, что в РНК стоп кодоны это UAG, UAA, UGA, а в ДНК, TAG, TAA, TGA.
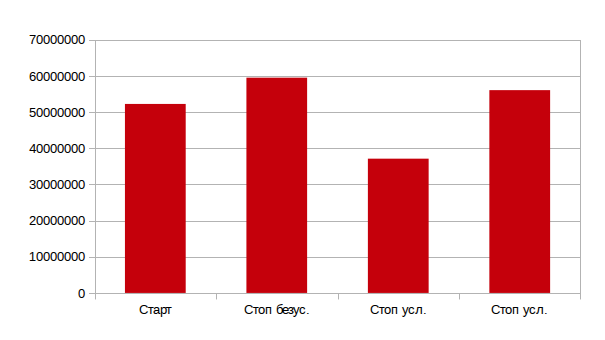
Сравним количество старт и стоп кодонов. Если кол-во старт кодонов ATG взять за 100%, то количество безусловных стоп кодонов TAA 113%, условных TAG кодонов 71%, а условных TGA кодонов 107%. В результате, на 100% старт кодонов, приходится в общей сложности 278% условных и абсолютных стоп кодонов. На диаграмме показано количество старт и стоп кодонов.
Следует учесть что в ДНК могут использоваться и другие старт и стоп кодоны. Например, кишечная палочка использует кодон ATG как старт кодон только в 83%, в 14% GTG, в 3% TTG. Стоп кодон TAA в 63% случаев, TGA в 29%, TAG в 8% и эти отношения коррелируется с количеством GC последовательности.
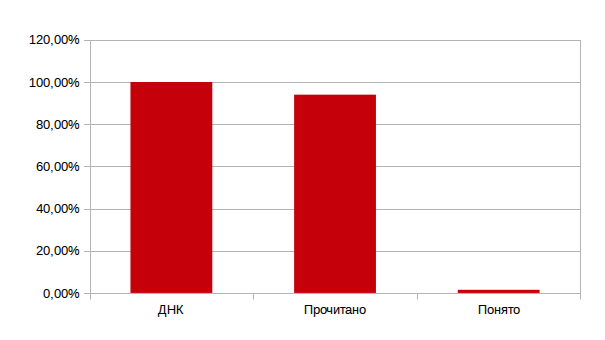
Еще одной проблемой для составления карты ДНК является качество чтения ДНК. На текущий момент непрочитанным остается примерно 6,02% ДНК. В основном это области теломеров (концов хромосомы) и центромеров (участков в центре хромосомы).
Значительная часть теломеров состоит из несколько тысяч повторяющихся последовательностей TTAGGG, которые не дают разрушится ДНК. Теломеры и центромеры содержат небольшое число генов, но они важны для функционирования и стабильности хромосом.
Так, только около 1,5% генома человека состоит из кодирующих белок последовательностей, а больше 50% ДНК человека состоит из некодирующих повторяющихся последовательностей ДНК. Причины наличия такого большого количества некодирующей ДНК и огромная разница в размерах геномов различных видов — одна из неразрешённых научных загадок. Также, исследования в этой области указывают на большое количество фрагментов реликтовых вирусов в ДНК.
Сравним общий размер ДНК, размер его прочитанной и расшифрованной области.
Для примера рассмотрим ген SLC36A4 ENSG00000180773, который, кстати говоря, имеет 7 вариантов прочтения. Посмотреть на его последовательности можно по этому адресу или щелкнув по картинке ниже. То что выделено красным цветом это ген.

Для сравнения возмем ген CEP295 ENSG00000166004. Посмотреть на его последовательности можно по этому адресу или щелкнув по картинке ниже.

Осмотр представленных генов демонстрирует что старт и стоп кодоны это последовательности, которые чаще других используются для начала или завершения кодирования белка, но не всегда именно они.
Каким образом находят гены и определяют их назначение? Общего алгоритма поиска генов и определения их назначения не существует. Иногда их находят случайно, иногда ищут сознательно, предполагая их место нахождение. Существует относительно универсальный метод Multiple EM for Motif Elicitation (MEME, многократное применение метода максимального правдоподобия для поиска мотивов, МПММППМ). МПММППМ — алгоритм поиска мотивов в биологических последовательностях белков и ДНК, однако он решает узкую задачу поиска места известной последовательности.
Уверен, среди нашей молодежи найдутся те, которые способны сделать так, чтобы еще через 73 года можно было составить карту ДНК человека на домашней ПЭВМ, также, как сегодня, через 73 года после открытия группы Чаргаффа, возможно подтвердить их открытия за 5 минут. Сегодня возможность составления единой, однозначной карты ДНК человека исключительно средствами вычислительных технологий объективно отсутствует.